Süni intellektə Azərbaycan dilini anlamağı öyrədək!
'Səsimiz' — könüllülərin gücü ilə işləyən subtitr redaktə platformasıdır. Məqsəd nitqi tanıyan süni intellektin nəhayət Azərbaycan dilini də yaxşı anlamasına nail olmaq.
Hər dəfə bir neçə dəqiqənizi film subtitrlərinin düzəldilməsinə ayırmaqla, hələ mövcud olmayan böyük, açıq və yüksək keyfiyyətli Azərbaycan dili nitq datasetinin yaranmasına kömək etmiş olarsınız. Üstəlik, proses zamanı filmlər də düzgün subtitrlər və tərcümələr qazanır.
Hazırki problem
Yəqin ki, səsli yazma, YouTube-da avtomatik subtitrlər və ya səsli köməkçilərdən istifadə etmisiniz. Onlar ingilis dilində heyrətamiz dərəcədə yaxşı işləyir. Bəs Azərbaycan dilində? O qədər də yox.
Bu texnologiyanın adı ASR (Automatic Speech Recognition — Avtomatik Nitq Tanıma), digər adı isə STT (Speech-To-Text — Nitqdən Mətnə): danışıq audiosunu yazılı mətnə çevirən süni intellekt modelləridi.
Bu modellər nitqi tanımağı insan beyninə bənzər şəkildə öyrənir — 'eşitdiklərindən'. Bir dildə nə qədər çox nitq materialı ilə öyrədilirlərsə, o dili bir o qədər yaxşı anlayar. Problem isə bir müqayisədə aydın görünür. Ən populyar açıq mənbəli ASR modellərindən biri olan Whisper-in təlim datasına baxaq:
| Dil | Təlim audiosu (saat) |
|---|---|
| İngilis | 438 218 |
| Rus | 9 761 |
| Türk | 4 333 |
| İtalyan | 2 585 |
| Azərbaycan | 47 |
Azərbaycan dilindəki təlim audiolarının toplam uzuluğu qırx yeddi saat. İngilis dilinin əlli illik materialı ilə müqayisədə iki gündən az audio. Whisper modellərdən yalnız biridir, amma əsas fakt hər yerdə eynidir: ictimaiyyətə açıq Azərbaycan dili nitq datası çox azdır. Bu belə qaldıqca, süni intellekt dilimizi anlamaqda çətinlik çəkməyə davam edəcək.
Dataset daha dəqiq nə deməkdir?
Nitq dataseti sadəcə qısa audio parçalarından ibarət böyük bir kolleksiyasıdır — hər parça öz dəqiq yazılı transkripsiyası ilə. Vəssalam. Modellər məhz bundan öyrənir. Problem ondadır ki, mətnin audioya tam uyğun gəldiyini yoxlamaq üçün insan əməyi lazımdır — özü də bir xeyli insan əməyi. Məhz burada siz köməyə gələ bilərsiniz.
'Səsimiz' necə işləyir
İdeya budur: təbii, danışıq dilində Azərbaycan nitqinin mənbəyi kimi filmlərdən istifadə etmək — və parallel olaraq həmin filmlər üçün düzgün subtitrlər və tərcümələr yaratmaq.
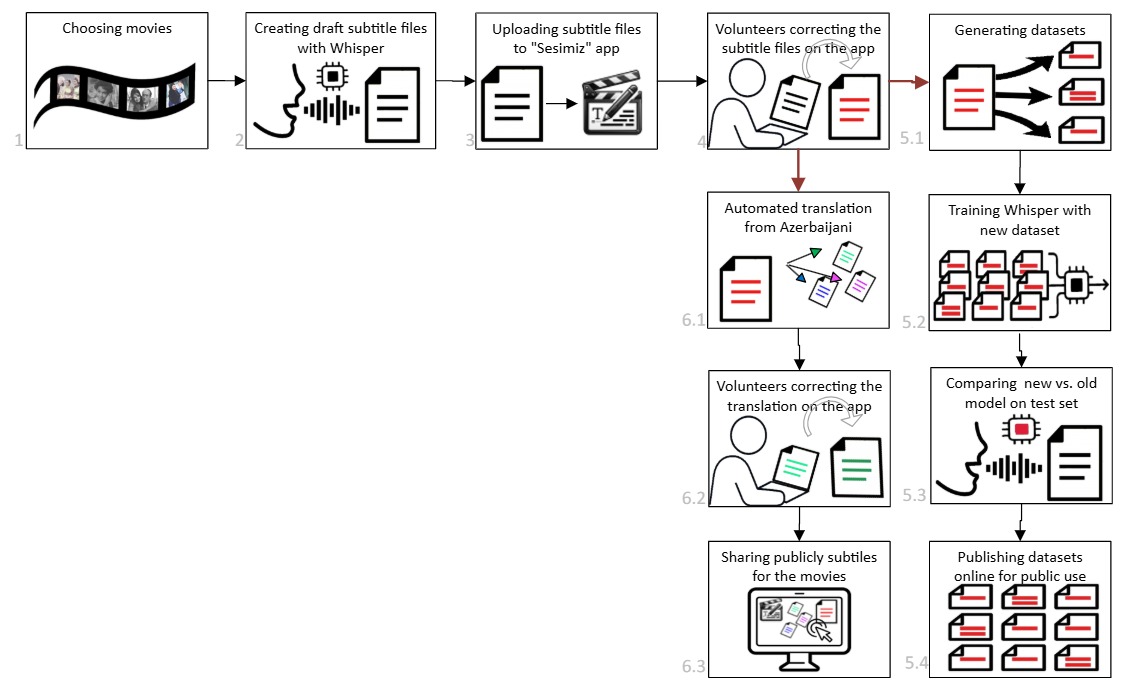
- Filmlər seçilir (hüquq sahiblərinin icazəsi ilə — siz də film təklif edə bilərsiniz!).
- Whisper avtomatik qaralama subtitrlər yaradır. Modelin hazırda nə qədər zəif olduğunu, qaralama subtirdə hazırda nə qədər səhvlərin olduğunu özünüz görəcəksiniz — layihənin bütün məqsədi məhz bunu yaxşılaşdırmaqdır.
- Qaralamalar 'Səsimiz' platformasına yüklənir və mövcud filmlər siyahısında görünür.
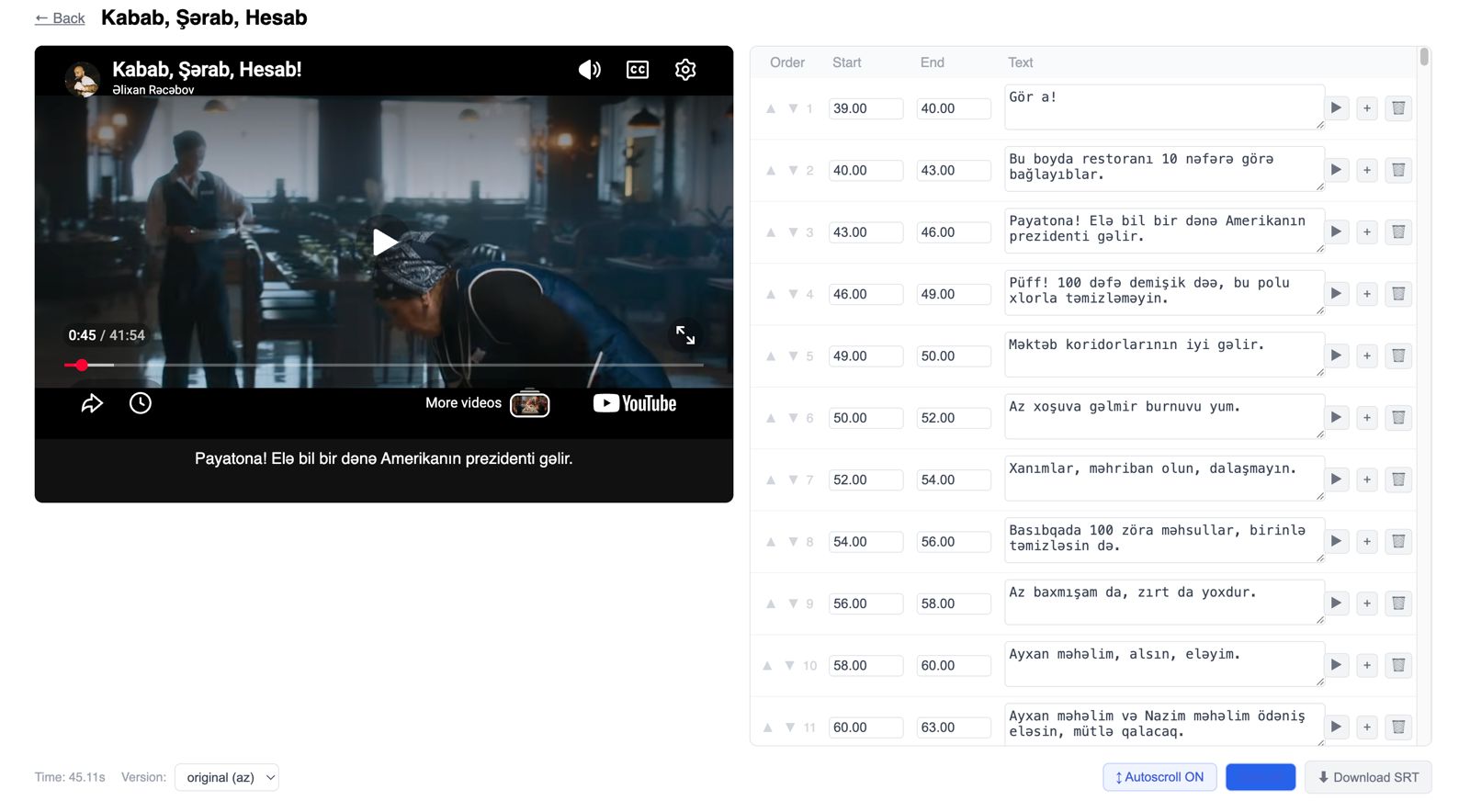
- Siz (könüllü olan hər kəs) platformaya daxil olursunuz, bir film seçirsiniz və öz tempinizlə filmlərə baxır, dinləyir və subtitrləri düzəldirsiniz. Hər düzəldilmiş fayl qəbul edilməzdən əvvəl keyfiyyət yoxlamasından keçir.
- 'Səsimiz' platformasında yaradılmış subtirlər xırda hissələrə bölünür və datasetlərin yaradılmasında istifadə olunur. Daha sonra bu datasetlər süni intellekt modellərinin mükəlləşməsi üçün istifadə olunur
Subtitrlər və tərcümələr: Azərbaycanca subtitrlər təsdiqləndikdən sonra onları başqa dillərə tərcümə etmək asanlaşır — maşın tərcüməsi qaralama verir, könüllülər və mən onu yoxlayırıq, hazır subtitr faylları isə pulsuz ictimaiyyətə açıq şəkildə paylaşılır.
Dataset yaradılması: xüsusi skript filmin tam audiosunu təsdiqlənmiş mətnlə uyğunlaşdırılmış qısa parçalara bölür. Nəticədə təmiz təlim dataseti alınır. Yeni dataset Whisper-in təkmilləşdirilməsi (fine-tuning) üçün istifadə olunacaq və nəticələr WER (söz xətası dərəcəsi) və başqa keyfiyyət meyarları əsasında müqayisə ediləcək. Sonda dataset açıq şəkildə Hugging Face kimi platformalarda dərc olunacaq.
Film icazələri haqqında
Filmlərdən yalnız icazə ilə istifadə edilir. İndiyədək Azərbaycanfilm Kinostudiyası ilə (cavablarını gözləyirəm) və Əlixan Rəcəbov əlaqə saxlamışam. Əlixan bütün YouTube filmlərindən istifadə icazəsi verib. Onun filmləri gündəlik danışıq nitqi ilə zəngindir — ASR modelinə lazım olan material məhz budur. Bunun üçün ona çox təşəkkür edirəm!
Daha çox kinorejissor və təşkilatlarla əlaqə saxlayacağam. Azərbaycan dilində filminiz və ya danışıqla zəngin uzun video materialınız (30+ dəqiqə) varsa və onun bu layihədə iştirakına icazə vermək istəyirsinizsə, buna şad olaram — əlaqə formasını doldurun, sizinlə əlaqə saxlayacağam.
Könüllü olmağınız üçün səbəblər:
- Birbaşa təsir: subtitrlərin düzəldilməsinə sərf etdiyiniz hər dəqiqə Azərbaycan dilində nitq tanımanı ölçülə bilən dərəcədə yaxşılaşdıran təlim datasına çevrilir — hamı üçün və həmişəlik, çünki dataset açıq olacaq.
- Real filmlər üçün real subtitrlər: bu gün mövcud olmayan subtitr və tərcümələrin yaranmasına kömək edəcəksiniz.
- Effekt artaraq toplanır: daha yaxşı ASR növbəti avtomatik subtitrləri yaxşılaşdırır, bu da düzəlişi sürətləndirir, bu da datasetin böyüməsini sürətləndirir.
- Təcrübə tələb olunmur: Azərbaycan dilini bilirsinizsə və yaza bilirsinizsə, kömək edə bilərsiniz. Hətta 15 dəqiqə də faydalıdır.
Tam şəffaflıq
Bu layihə mənim diplom işimdir. Ondan heç bir pul qazanmıram və platformada heç nə pullu deyil. Tədqiqat və diplom işinin yekun təqdimatı üçün platforma könüllülərin subtitrlər üzərində nə qədər vaxt işlədiyini qeyd edir — bu məlumat yalnız ümumi töhfə həcminin ölçülməsi üçün istifadə olunur.
Hörmətlə,
Zülfiyyə
Könüllü olmaq istərdiniz?
Email ünvanınızı və adınızı qeyd edin, sizinlə əlaqə saxlayacam.